Optimizing Object Stores For Data with lakeFS
The first problem faced with big data was the feasibility of processing data at such a high scale. In solving the scale problem, people developed technologies we know today like Kafka, Spark, Presto, Snowflake, etc.
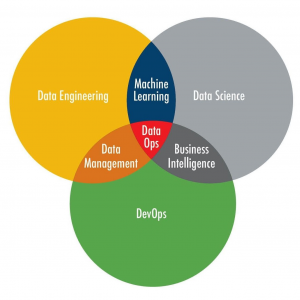
Now the problem people face is one of manageability. People no longer ask if they can handle a dataset but rather: How can I move faster when developing data-intensive applications? How do I utilize all of my data and ensure it is high-quality?
Learn how lakeFS simplifies managing a data lake by enabling git-like operations over files in object storage. Workflows around experimentation, reproducing datasets, and guaranteeing data quality are simplified with the primitives provided by data source control. The result is a developer experience that is optimized for modern data lakes.
Widzisz błąd w opisie lub danych wydarzenia?
Zaloguj się, by zgłosić zmianę.